Comparisons·
Is Playwright Free? Yes — Here's What It Costs at Scale
Playwright is free and open source. At 50–200 engineer teams, maintaining it costs an SDET hire. See the creation, flake, and CI math.
Playwright is free and open source. At 50–200 engineer teams, maintaining it costs an SDET hire. See the creation, flake, and CI math.

Playwright won the framework war. AI agents won the maintenance war. Why mid-market SaaS teams move from Playwright code to AI-led regression.

Five things change in a QA Lead job when AI QA testing arrives, and three things do not. A POV pillar grounded in 41 interviews with mid-market SaaS QA leaders.

A buyer-side handbook to AI test automation tools in 2026. Four tool buckets, 10 platforms mid-market teams evaluated this year, a 9-criterion scorecard, TCO math, and a 30-day evaluation playbook.

A 4,500-word pillar guide to AI testing for engineering teams. What it is, what it solves, what it doesn’t, the 8-feature buyer checklist, cost framing, and a 30-day rollout plan.

The 8-feature scorecard for buying an AI testing tool in 2026: discovery, authoring, healing, CI/CD, telemetry, cost, ownership, and exit. With red flags, the 30-day POC playbook, and the green-pipeline test.

A practitioner guide to writing, debugging, and shipping Playwright tests with Claude Code. Patterns that work, patterns that break, and when to graduate to a dedicated tool.
Most Playwright vs Selenium posts pick a winner. The real 2026 question is what AI-led testing changes about both frameworks. Honest comparison and the deeper question.

How to buy QA services in 2026: the four models, the 10-question scorecard, real pricing, contract red flags, and when DIY-on-AI beats buying.

A 5,000-word pillar guide to regression testing software in 2026. What it is, the seven categories, a 9-criteria buyer scorecard, pricing models compared, cost framing, and a 30-day implementation playbook.

First-hand verdicts on 10 regression testing tools: 5 automated (Playwright, Cypress, Selenium, Mabl, QAby.AI) and 5 visual (Applitools, Percy, Chromatic, Loki, QAby.AI visual mode).

A 90-day, framework-by-framework playbook that turns release confidence into a measurable system. Audit, pilot, expand. The Monday-morning checklist mid-market eng leaders actually need.

Selenium is durable, polyglot, and still everywhere. The honest question is when a modern AI testing alternative is worth the migration cost, and when it is not.

41 QA teams later, the "just use ChatGPT to write your tests" advice fails on review burden, accuracy ceiling, and activation. Here is what we found.

59 email-flow steps across 5 users and 4 teams on QAby.AI. The niche QA pain no vendor markets to, with real telemetry on OTP, magic-link, and password-reset testing.

A green pipeline means everything passed. It does not mean everything was checked. The pattern, the case, and the one question to ask any AI testing vendor.

A coined framework backed by n=26 calls. Selector and locator maintenance consume 20–30% of Playwright, Selenium, and Cypress automation time. Here is the math, the pattern, and the fix.

187 MCP clients, 1.42M agent tool calls, three very different usage shapes. The data POV on which coding agent actually uses browser-automation MCP the most.

Coined framework: when QA teams stop looking at their own bug alert channel because volume overwhelms signal. Anchored in 41 real conversations.

What it actually costs to maintain a Playwright suite, broken down by team shape. Data from 41 mid-market SaaS QA interviews and US SDET salary bands.

230,105 npm downloads, 1.42M agent tool calls, 187 MCP clients, 5,904 domains tested. The activation cliff, the screenshot habit, and the localhost truth.

Ship-and-Pray is the culture of releasing at 80% functionality and fixing in production. We name it, source it, and show why the customer became the integration test.

The Single-Throat Bottleneck is the pattern where one QA person is the only sign-off on every release. The diagnostic, the cost, and how to widen the gate.

Most AI testing buyers should not buy AI testing yet. A 5-question self-diagnostic for when curiosity becomes need-now. Honest framing from 41 customer calls.

27 of 41 mid-market SaaS leaders we interviewed paused their next SDET hire. The State of AI QA 2026 report explains why and what they did instead.

9,103 real test steps from 14 mid-market SaaS teams decoded. Median test is 8 steps. 1 in 8 is an AI assertion. What AI testing actually looks like.

A five-rung diagnostic for the signal QA captures vs. what dev needs to fix a bug. Screenshots, video, console logs, traces, live debugger, and where most teams stall.

The N-3 Automation Lag is the structural pattern where regression coverage trails feature dev by 3 sprints. The math, the cost, and how to collapse it.

Playwright is great. The honest question is when an AI testing alternative is worth migrating to, and when it is not. A grounded read.

n=41 calls, 9,103 test steps, 230k Playwright MCP downloads. The 2026 benchmark on QA team size, the locator tax, and the agentic testing layer.

Coined framework: the QA bottleneck is not writing tests, it is knowing what to test. Diagnostic, math, and a fix anchored in 41 real conversations.

QAby.AI defers the $200K SDET hire your engineering team would otherwise need next quarter. Here is the math on what it really costs.

Every demo passes. Most production deployments stall. Two evaluation tests your engineers can run on any AI QA vendor before the 12-month contract.
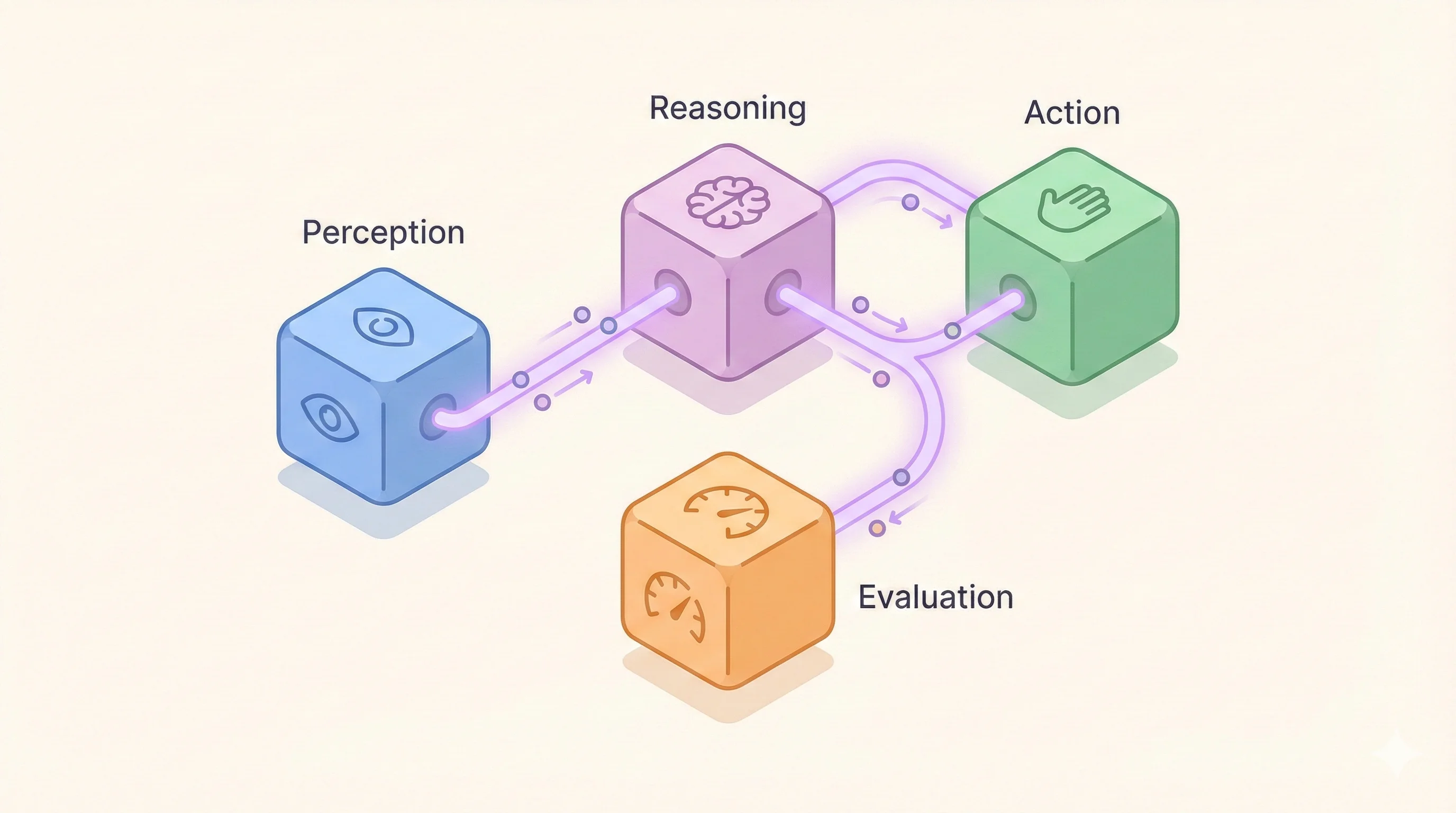
TypeScript isn't optional. Start with evals before code. Track every LLM call. Your architecture choices determine whether you ship or debug forever.

Understanding the 4-part loop that powers production AI agents: Perception, Reasoning, Action, and Feedback